Where Does It Exist: Spatio-Temporal Video Grounding for Multi-Form Sentences ComputerVisionFoundation Videos 1:00 4 years ago 273 Далее Скачать
TubeDETR: Spatio Temporal Video Grounding With Transformers | CVPR 2022 Artificial Intelligence 5:00 2 years ago 214 Далее Скачать
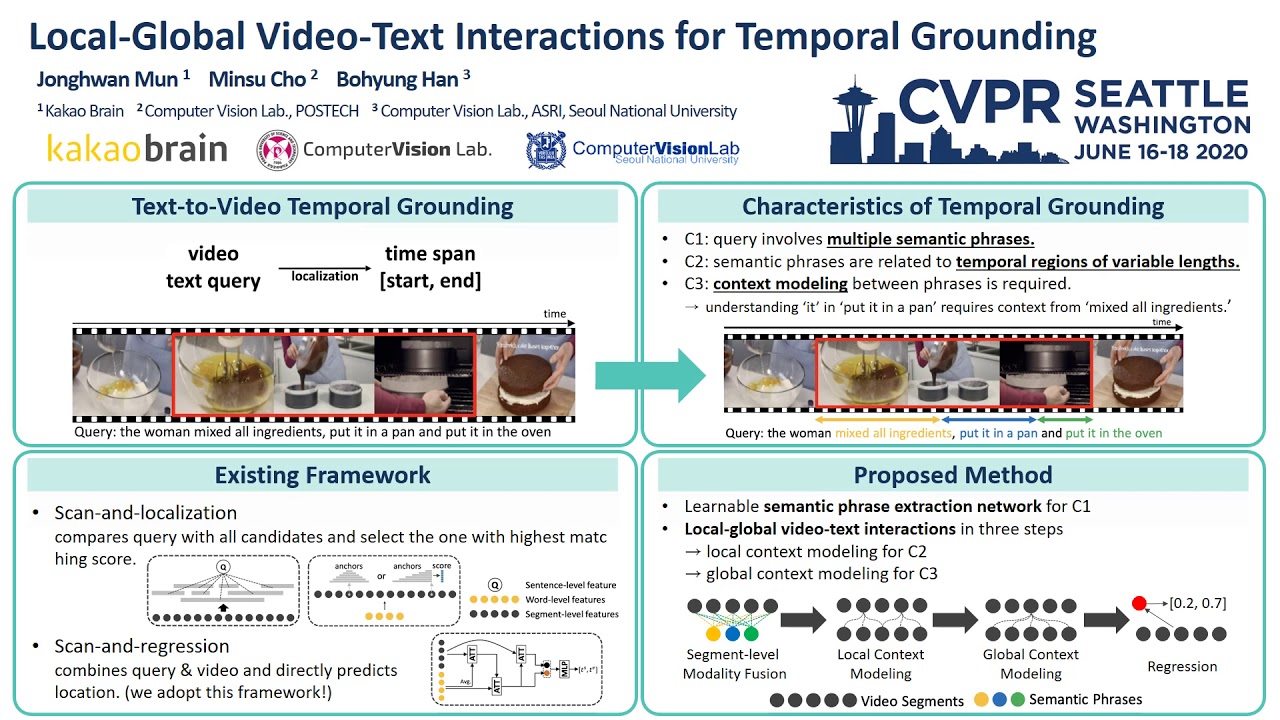
Local-Global Video-Text Interactions for Temporal Grounding ComputerVisionFoundation Videos 1:01 4 years ago 161 Далее Скачать
Towards Grounded Spatio-Temporal Reasoning Microsoft Research 1:24:23 5 years ago 1 183 Далее Скачать
Weakly Supervised Temporal Sentence Grounding With Uncertainty-Guided Self-Training Yifei 7:30 1 year ago 57 Далее Скачать
CVPR23: Collaborative Static and Dynamic Vision-Language Streams for Spatio-Temporal Video Grounding 林子杭 7:38 1 year ago 24 Далее Скачать
Exploring Spatial-Temporal Multi-Frequency Analysis for High-Fidelity and Temporal-Consistency... ComputerVisionFoundation Videos 1:01 4 years ago 206 Далее Скачать
Spatiotemporal Fusion in 3D CNNs: A Probabilistic View Microsoft Research 4:59 4 years ago 543 Далее Скачать
MoReVis: A Visual Summary for Spatiotemporal Moving Regions - Fast Forward | VIS 2023 IEEE Visualization Conference 0:31 1 year ago 13 Далее Скачать
Making Sense of Temporal Queries with Interactive Visualization ACM SIGCHI 0:31 8 years ago 448 Далее Скачать
Consistent Cell Tracking in Multi-frames with Spatio-Temporal Context by Object-Level Warping Loss ComputerVisionFoundation Videos 4:57 2 years ago 217 Далее Скачать
MoReVis: A Visual Summary for Spatiotemporal Moving Regions | VIS 2023 IEEE Visualization Conference 10:45 1 year ago 25 Далее Скачать
Beyond Short-Term Snippet: Video Relation Detection With Spatio-Temporal Global Context ComputerVisionFoundation Videos 1:01 4 years ago 155 Далее Скачать
A Spatio-Temporal Feature based on Triangulation of Dense SURF UCF CRCV 17:59 10 years ago 306 Далее Скачать
Video Object Grounding Using Semantic Roles in Language Description ComputerVisionFoundation Videos 1:01 4 years ago 100 Далее Скачать
Anna Rohrbach: Grounding and Generation of Natural Language Descriptions for Images and Videos Ai2 51:06 8 years ago 913 Далее Скачать
Object Relational Graph With Teacher-Recommended Learning for Video Captioning ComputerVisionFoundation Videos 1:05 4 years ago 135 Далее Скачать